SharePoint, PnP, SPFx
Date: 2025 08-August 23
CB 0
Can i leverage yeoman to populate sharepoint metadata and columns and document sets?
CG 0
Yes — but not in the way Yeoman is typically used out of the box.
Yeoman itself is just a **scaffolding tool**: it runs generators that create/configure files and optionally automate setup steps. It doesn’t natively talk to SharePoint to create lists, libraries, metadata, or document sets.
That said, you _can_ leverage Yeoman in combination with the **PnP toolchain (PowerShell or CLI)** to achieve what you’re describing:
---
### How it fits together
1. **Yeoman Generator**
- You write or adapt a Yeoman generator that scaffolds a configuration file (JSON, XML, YAML, etc.) describing your SharePoint content types, site columns, metadata, and document set definitions.
- This can be parameterized: e.g., a prompt asks for “project name,” “business unit,” etc.
2. **PnP PowerShell / CLI for Microsoft 365**
- After generating config files, the Yeoman generator can run scripts that apply them to SharePoint.
- For example:
- `m365 spo contenttype add ...`
- `m365 spo field add ...`
- `m365 spo list add ...`
- `m365 spo list contenttype add ...`
- `m365 spo documentset add ...`
3. **Document Sets**
- Document sets in SharePoint are essentially a **content type** derived from “Document Set,” with associated metadata and default content.
- PnP PowerShell (`Add-PnPContentType`, `Add-PnPField`, `Enable-PnPFeature -Identity DocumentSet`) or CLI equivalents can set this up.
- Yeoman’s role here is to scaffold the JSON + script definitions so you don’t manually repeat work across sites.
---
### Example workflow
- Run `yo sp-meta` (your custom generator).
- Yeoman asks:
- “What site collection URL?”
- “Which columns do you need?”
- “Do you want a document set content type?”
- Generator outputs a JSON definition and a `deploy.ps1` (PnP PowerShell) script.
- You run `deploy.ps1`, and it provisions the site columns, content types, and document sets into SharePoint.
---
### Why Yeoman helps
- Standardizes provisioning across projects/teams.
- Makes metadata definitions repeatable and portable (scaffold → script → deploy).
- Encourages version control of SharePoint schema definitions.
---
✅ **Answer:** You can’t use Yeoman _directly_ to provision SharePoint metadata and document sets. But you _can_ build a Yeoman generator that scaffolds the definitions (JSON/PowerShell/CLI) which then use **PnP PowerShell or CLI for Microsoft 365** to actually populate SharePoint.
---
Do you want me to sketch an example Yeoman generator template that scaffolds a **document set definition** + **PnP PowerShell script** for you?
CB 1
Tell me more about just the PnP aspect. What are all of the opportunities? Which opportunities can leverage intelligent assessment?
CG 1:
Got it — let’s zoom in on the **PnP side only** (without Yeoman). PnP is where the _real_ SharePoint provisioning power is, and it’s broader than many people realize.
---
## 🔑 PnP Opportunities for SharePoint Metadata, Columns, and Document Sets
### 1. **Site Columns (Fields)**
- Add, update, or remove fields (`Add-PnPField`, `Set-PnPField`).
- Define types: text, choice, number, currency, lookup, managed metadata, date/time, etc.
- Configure field settings: required, default value, indexed, unique values, enforce relationship behavior.
- Intelligent angle: **Analyze content usage** → suggest which fields should be indexed for query performance.
---
### 2. **Content Types**
- Create content types (`Add-PnPContentType`) and attach fields.
- Bind content types to libraries/lists (`Add-PnPContentTypeToList`).
- Hierarchies of content types (inheritance from base types).
- Intelligent angle: **Assess document libraries** → recommend common metadata → propose a unified content type taxonomy.
---
### 3. **Document Sets**
- Enable document set feature (`Enable-PnPFeature -Identity DocumentSet`).
- Create a document set content type.
- Define allowed content types inside the set.
- Define default documents and metadata inheritance rules.
- Intelligent angle: **Look at patterns of grouped documents** (e.g., project files, contracts) → propose document set templates.
---
### 4. **Lists & Libraries**
- Provision new libraries with metadata, views, and content type bindings (`Add-PnPList`).
- Apply retention labels, default column values, and versioning.
- Intelligent angle: **Review growth trends** → recommend partitioning or archive libraries.
---
### 5. **Managed Metadata (Term Store)**
- Provision term groups, term sets, and terms (`Add-PnPTerm`, `Add-PnPTermSet`).
- Bind term sets to fields for managed metadata columns.
- Intelligent angle: **Natural language analysis of document titles/tags** → propose hierarchical term sets automatically.
---
### 6. **Provisioning Templates**
- Save a site’s structure/metadata as a PnP provisioning template (`Get-PnPProvisioningTemplate`).
- Apply to another site (`Apply-PnPProvisioningTemplate`).
- Templates can define:
- Fields
- Content types
- Document libraries
- Lists
- Pages
- Branding
- Intelligent angle: **Compare templates across departments** → detect drift and suggest harmonization.
---
### 7. **Policies & Governance**
- Apply retention labels and sensitivity labels.
- Enforce check-in/check-out, major/minor versioning.
- Intelligent angle: **Analyze document lifecycle** → suggest policies (e.g., auto-archive financial docs after 7 years).
---
### 8. **Automation & CI/CD**
- Integrate PnP provisioning into pipelines (Azure DevOps, GitHub Actions).
- Deploy consistent SharePoint metadata and structures across environments.
- Intelligent angle: **Health checks** in CI → warn about inconsistencies (e.g., missing site columns or mismatched content types).
---
## 🎯 Where "Intelligent Assessment" Adds Value
PnP gives the _mechanics_, but you can apply intelligence (automation, analytics, or AI) to **decide what should be provisioned**:
1. **Metadata Recommendations**
- Analyze existing document libraries for frequently used properties → recommend new site columns.
- Use ML/NLP on filenames and document content to suggest fields.
2. **Document Set Detection**
- Grouping analysis → detect when users always create the same “bundle” of files → suggest a document set.
3. **Performance & Query Optimization**
- Assess query performance → recommend which columns to index.
- Spot large lookup fields or unmanaged metadata that should be cleaned up.
4. **Taxonomy Management**
- Identify duplicate or overlapping terms in the term store.
- Suggest merging or restructuring taxonomy.
5. **Governance Gaps**
- Flag libraries without retention or sensitivity labels.
- Recommend policies based on document type.
---
✅ **Summary:**
PnP gives you a _huge toolbox_ for **site columns, content types, document sets, term store, libraries, templates, and governance**.
The **intelligent assessment opportunities** are in **analyzing existing usage patterns, performance, and content** to recommend _what to build or adjust with PnP_, not just how to build it.
---
Would you like me to give you a **concrete PnP script example** for provisioning a **document set content type with custom metadata**, and then I can layer on where “intelligent assessment” would tweak it?
CG 2:
Perfect 👍 — here’s a **PnP PowerShell** script that provisions a **document set content type with custom metadata** in SharePoint Online. I’ll annotate it so you can see what each part does, and then I’ll highlight where “intelligent assessment” could be inserted.
📜 Example: Provision a Document Set Content Type
# Connect to SharePoint Online
# (replace URL with your site and use interactive login or app auth)
Connect-PnPOnline -Url "https://contoso.sharepoint.com/sites/Projects" -UseWebLogin
# 1. Enable Document Set feature (needed once per site collection)
Enable-PnPFeature -Identity "3bae86a2-776d-499d-9db8-fa4cdc7884f8" -Scope Site
# 2. Create custom site columns (fields)
Add-PnPField -DisplayName "Project Code" -InternalName "ProjectCode" -Type Text -Group "Custom Columns"
Add-PnPField -DisplayName "Client Name" -InternalName "ClientName" -Type Text -Group "Custom Columns"
Add-PnPField -DisplayName "Start Date" -InternalName "StartDate" -Type DateTime -Group "Custom Columns"
Add-PnPField -DisplayName "End Date" -InternalName "EndDate" -Type DateTime -Group "Custom Columns"
# 3. Create a new Document Set content type
# Base content type for document set is 0x0120D520
Add-PnPContentType -Name "Project Document Set" -Description "Container for project documents" -ParentContentType "Document Set" -Group "Custom Content Types"
# 4. Attach fields to the new content type
Add-PnPContentTypeField -Field "ProjectCode" -ContentType "Project Document Set"
Add-PnPContentTypeField -Field "ClientName" -ContentType "Project Document Set"
Add-PnPContentTypeField -Field "StartDate" -ContentType "Project Document Set"
Add-PnPContentTypeField -Field "EndDate" -ContentType "Project Document Set"
# 5. Add the Document Set content type to a library
Add-PnPList -Title "Projects Library" -Template DocumentLibrary -OnQuickLaunch
Add-PnPContentTypeToList -List "Projects Library" -ContentType "Project Document Set"
# 6. (Optional) Set default content inside the Document Set
# Example: add a Word template and a task list
Set-PnPDocumentSetTemplate -ContentType "Project Document Set" `
-SharedColumns "ProjectCode","ClientName","StartDate","EndDate" `
-WelcomePageFields "ProjectCode","ClientName" `
-AllowedContentTypes "Document" `
-DefaultDocuments @(
@{ Name="Project Charter.docx"; ContentType="Document"; FileSource="C:\Templates\ProjectCharter.docx" }
)
## 🔍 Where "Intelligent Assessment" Fits
- **Columns** → Instead of hardcoding, an intelligent engine could scan your existing document library, detect frequent filename tokens (`Project123`, `ClientX`), and suggest fields like _Project Code_ and _Client Name_.
- **Default documents** → Assess project teams’ habits (they always upload a Charter, Risk Register, etc.) and automatically add them to the Document Set defaults.
- **Content type reuse** → Analyze multiple libraries; if they all use similar metadata, the system can recommend consolidating into a shared content type.
- **Governance checks** → Script could validate if retention labels or sensitivity labels are missing and apply recommended defaults.
---
👉 This script provisions a **working Document Set content type** in a fresh site. Once run, users will see a **“Project Document Set”** option when creating items in the “Projects Library,” and each document set will carry your custom metadata.
---
Do you want me to also show you the **PnP CLI (m365)** equivalent? It’s more portable (cross-platform, runs in CI/CD), whereas PowerShell is richer for admin scripting.
CB 4:
Yes
Also mentioned which library can be used in powershell as an intelligent engine
CG 4:
Excellent — let’s cover both:
⚡ PnP CLI (m365) Equivalent
The CLI for Microsoft 365 (aka m365) is cross-platform (Windows, Linux, macOS) and works great in CI/CD pipelines. Here’s the same Document Set content type with custom fields in CLI form:
# 1. Login
m365 login --authType browser
# 2. Enable Document Set feature
m365 spo feature enable --url "https://contoso.sharepoint.com/sites/Projects" \
--id 3bae86a2-776d-499d-9db8-fa4cdc7884f8 --scope Site
# 3. Create site columns
m365 spo field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--type Text --name "ProjectCode" --displayName "Project Code" --group "Custom Columns"
m365 spo field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--type Text --name "ClientName" --displayName "Client Name" --group "Custom Columns"
m365 spo field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--type DateTime --name "StartDate" --displayName "Start Date" --group "Custom Columns"
m365 spo field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--type DateTime --name "EndDate" --displayName "End Date" --group "Custom Columns"
# 4. Create Document Set content type
m365 spo contenttype add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--name "Project Document Set" \
--description "Container for project documents" \
--parentContentType "0x0120D520" \
--group "Custom Content Types"
# 5. Add fields to the content type
m365 spo contenttype field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--contentTypeName "Project Document Set" --fieldName "ProjectCode"
m365 spo contenttype field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--contentTypeName "Project Document Set" --fieldName "ClientName"
m365 spo contenttype field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--contentTypeName "Project Document Set" --fieldName "StartDate"
m365 spo contenttype field add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--contentTypeName "Project Document Set" --fieldName "EndDate"
# 6. Create a library and add the content type
m365 spo list add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--title "Projects Library" --baseTemplate DocumentLibrary
m365 spo list contenttype add --webUrl "https://contoso.sharepoint.com/sites/Projects" \
--listTitle "Projects Library" --contentTypeName "Project Document Set"
👉 As of now, m365 doesn’t have a direct command to configure Document Set templates (defaults, shared fields, etc.) — for that you still need PnP PowerShell. But CLI covers fields, content types, lists/libraries, and works seamlessly in DevOps.
🧠 Intelligent Engine Options in PowerShell
If you want PowerShell itself to act “intelligently” (e.g., recommend metadata, detect patterns, or assess usage), you’ll need to bring in data science or ML libraries. A few good options:
1. ML.NET via .NET interop
-
PowerShell can load .NET assemblies.
-
You can train classification/regression models on document properties.
-
Example: Predict “likely project fields” from file naming patterns.
2. Python Interop (Best for AI/ML)
-
Use PowerShell + Python (via
python.exeorpycommands). -
Python libraries (Pandas, scikit-learn, spaCy, transformers) can analyze SharePoint exports (CSV/Excel from PnP) → feed recommendations back into PowerShell provisioning.
-
This is the most practical “intelligent engine” today.
3. PowerShell Native + Azure Cognitive Services
-
Call REST APIs (Text Analytics, Form Recognizer, Search) directly from PowerShell.
-
Example: Extract key entities (Project ID, Client, Dates) from uploaded documents → recommend site columns.
4. R Libraries via Rscript
- Similar to Python interop, but less common.
🚀 Practical Approach
-
PnP PowerShell does the provisioning.
-
Python (scikit-learn, spaCy, transformers) does the intelligent assessment (metadata suggestions, content clustering, taxonomy recommendations).
-
PowerShell calls Python → Python outputs a config JSON → PowerShell applies it via PnP.
✅ Summary:
-
Use PnP PowerShell for deep SharePoint features (Document Set templates, provisioning templates, governance).
-
Use PnP CLI (m365) for cross-platform automation and CI/CD.
-
For intelligence: leverage Python ML libraries (or Azure Cognitive APIs) from PowerShell to analyze content and generate metadata recommendations.
Would you like me to sketch a pipeline example where:
-
PowerShell exports document library metadata →
-
Python analyzes it and suggests site columns →
-
PowerShell re-ingests the JSON and provisions fields via PnP?
CB 5
This conversation is great. Yet, please sketch the metadata schema and the useful pipeline example.
CG 5:
Great — let’s design this in two layers:
-
Metadata Schema (what we’re defining in SharePoint)
-
Pipeline Example (how PowerShell + Python + PnP interact)
🏗 Metadata Schema (JSON)
This is a structured way to define site columns, content types, and document sets. Think of it as the “source of truth” that PnP applies.
{
"siteColumns": [
{
"internalName": "ProjectCode",
"displayName": "Project Code",
"type": "Text",
"group": "Custom Columns",
"required": true,
"indexed": true
},
{
"internalName": "ClientName",
"displayName": "Client Name",
"type": "Text",
"group": "Custom Columns",
"required": false
},
{
"internalName": "StartDate",
"displayName": "Start Date",
"type": "DateTime",
"group": "Custom Columns"
},
{
"internalName": "EndDate",
"displayName": "End Date",
"type": "DateTime",
"group": "Custom Columns"
}
],
"contentTypes": [
{
"name": "Project Document Set",
"description": "Container for project documents",
"parent": "0x0120D520",
"group": "Custom Content Types",
"fields": ["ProjectCode", "ClientName", "StartDate", "EndDate"],
"documentSetConfig": {
"sharedColumns": ["ProjectCode", "ClientName"],
"welcomePageFields": ["ProjectCode", "ClientName"],
"allowedContentTypes": ["0x0101"],
"defaultDocuments": [
{
"name": "Project Charter.docx",
"contentType": "Document",
"fileSource": "C:\\Templates\\ProjectCharter.docx"
}
]
}
}
],
"libraries": [
{
"title": "Projects Library",
"contentTypes": ["Project Document Set"],
"versioning": "Major",
"retentionLabel": "Project Records"
}
]
}
👉 This schema can be hand-written or generated by Python after analyzing library contents.
👉 PowerShell reads it and calls PnP commands to apply it.
⚙️ Pipeline Example (Intelligent + Provisioning)
Step 1 — Export current metadata (PowerShell)
# Export library metadata to CSV for analysis
Connect-PnPOnline -Url "https://contoso.sharepoint.com/sites/Projects" -UseWebLogin
Get-PnPListItem -List "Documents" -PageSize 500 |
Select-Object FileLeafRef, FileDirRef, Modified, Editor |
Export-Csv "library_export.csv" -NoTypeInformation
Step 2 — Analyze with Python (intelligent assessment)
import pandas as pd
from collections import Counter
import json
import re
# Load export
df = pd.read_csv("library_export.csv")
# Extract patterns from filenames (e.g., "PRJ001_ClientX_Charter.docx")
project_codes = []
clients = []
for fname in df["FileLeafRef"]:
parts = re.split(r"[_\- ]", str(fname))
for p in parts:
if re.match(r"PRJ\d+", p):
project_codes.append(p)
elif "Client" in p or "Corp" in p:
clients.append(p)
# Suggest fields if patterns exist
schema = {"siteColumns": []}
if project_codes:
schema["siteColumns"].append({
"internalName": "ProjectCode",
"displayName": "Project Code",
"type": "Text",
"group": "Suggested Columns",
"required": True
})
if clients:
schema["siteColumns"].append({
"internalName": "ClientName",
"displayName": "Client Name",
"type": "Text",
"group": "Suggested Columns"
})
# Save schema JSON
with open("suggested_schema.json", "w") as f:
json.dump(schema, f, indent=2)
print("Suggested schema written to suggested_schema.json")
👉 This script scans filenames, extracts patterns, and proposes metadata fields.
👉 More advanced: run NLP on document content (via Azure Cognitive Search, spaCy, etc.).
Step 3 — Provision in SharePoint (PowerShell)
# Read suggested schema from Python
$schema = Get-Content "suggested_schema.json" | ConvertFrom-Json
# Loop through site columns and provision them
foreach ($field in $schema.siteColumns) {
Add-PnPField -DisplayName $field.displayName `
-InternalName $field.internalName `
-Type $field.type `
-Group $field.group
}
🚀 Resulting Workflow
-
Export → PnP pulls existing document library data.
-
Assess → Python analyzes file/content → suggests new metadata schema.
-
Provision → PowerShell ingests JSON and provisions via PnP.
✅ This creates a feedback loop where SharePoint usage drives metadata evolution.
✅ Over time, your system “learns” what metadata fields make sense, instead of IT guessing.
Would you like me to expand the JSON schema to also cover term store (taxonomy) so the pipeline can recommend managed metadata sets too?
Perfect 👍 — let’s extend the schema so it covers Term Store (Managed Metadata) alongside columns, content types, document sets, and libraries. Then I’ll show how it ties into the pipeline.
🏗 Extended Metadata Schema with Term Store
{
"siteColumns": [
{
"internalName": "ProjectCode",
"displayName": "Project Code",
"type": "Text",
"group": "Custom Columns",
"required": true,
"indexed": true
},
{
"internalName": "ClientName",
"displayName": "Client Name",
"type": "Text",
"group": "Custom Columns",
"required": false
},
{
"internalName": "ProjectCategory",
"displayName": "Project Category",
"type": "TaxonomyFieldType",
"group": "Custom Columns",
"termSet": "Project Categories"
}
],
"contentTypes": [
{
"name": "Project Document Set",
"description": "Container for project documents",
"parent": "0x0120D520",
"group": "Custom Content Types",
"fields": ["ProjectCode", "ClientName", "ProjectCategory"],
"documentSetConfig": {
"sharedColumns": ["ProjectCode", "ClientName", "ProjectCategory"],
"welcomePageFields": ["ProjectCode", "ClientName"],
"allowedContentTypes": ["0x0101"],
"defaultDocuments": [
{
"name": "Project Charter.docx",
"contentType": "Document",
"fileSource": "C:\\Templates\\ProjectCharter.docx"
}
]
}
}
],
"libraries": [
{
"title": "Projects Library",
"contentTypes": ["Project Document Set"],
"versioning": "Major",
"retentionLabel": "Project Records"
}
],
"termStore": {
"groups": [
{
"name": "Business Taxonomy",
"termSets": [
{
"name": "Project Categories",
"terms": [
{ "name": "Infrastructure" },
{ "name": "Water Treatment" },
{ "name": "Sewer Expansion" },
{ "name": "Stormwater" }
]
}
]
}
]
}
}
⚙️ Pipeline Example with Term Store
Step 1 — Export existing metadata & terms
Connect-PnPOnline -Url "https://contoso.sharepoint.com/sites/Projects" -UseWebLogin
# Export all terms from a given Term Store group
Get-PnPTerm -TermGroup "Business Taxonomy" -TermSet "Project Categories" |
Select-Object Name, Id, Path |
Export-Csv "terms_export.csv" -NoTypeInformation
Step 2 — Intelligent analysis in Python
import pandas as pd
import json
# Load document library export
docs = pd.read_csv("library_export.csv")
# Load existing terms
terms = pd.read_csv("terms_export.csv")
# Look for frequent keywords in filenames that aren’t yet in the term set
new_terms = []
keywords = ["Stormwater", "Drainage", "Treatment", "Expansion"]
for kw in keywords:
if not any(kw.lower() in t.lower() for t in terms["Name"]):
if docs["FileLeafRef"].str.contains(kw, case=False).any():
new_terms.append({"name": kw})
# Build a suggested schema update
schema_update = {
"termStore": {
"groups": [
{
"name": "Business Taxonomy",
"termSets": [
{
"name": "Project Categories",
"newTerms": new_terms
}
]
}
]
}
}
with open("suggested_terms.json", "w") as f:
json.dump(schema_update, f, indent=2)
print("Suggested new terms written to suggested_terms.json")
👉 Python has scanned documents → found “Stormwater” and “Drainage” → proposed adding them as new terms to the taxonomy.
Step 3 — Apply new terms with PowerShell
# Load suggested terms
$schema = Get-Content "suggested_terms.json" | ConvertFrom-Json
foreach ($group in $schema.termStore.groups) {
foreach ($set in $group.termSets) {
foreach ($term in $set.newTerms) {
Add-PnPTerm -TermGroup $group.name -TermSet $set.name -Name $term.name
}
}
}
🚀 Result
-
Export → Get existing taxonomy and library data.
-
Assess → Python/NLP finds new terms based on filenames/content.
-
Provision → PowerShell provisions missing terms into the Term Store.
-
Schema evolves → New metadata fields + managed terms are auto-suggested, making libraries more consistent and searchable.
✅ With this extension, the pipeline now handles:
-
Columns (site fields)
-
Content types (document sets, metadata inheritance)
-
Libraries (with governance settings)
-
Managed metadata (term store) with intelligent suggestions
Would you like me to sketch a visual flow diagram of this full pipeline (Export → Assess → Provision) so you can see the loop clearly?
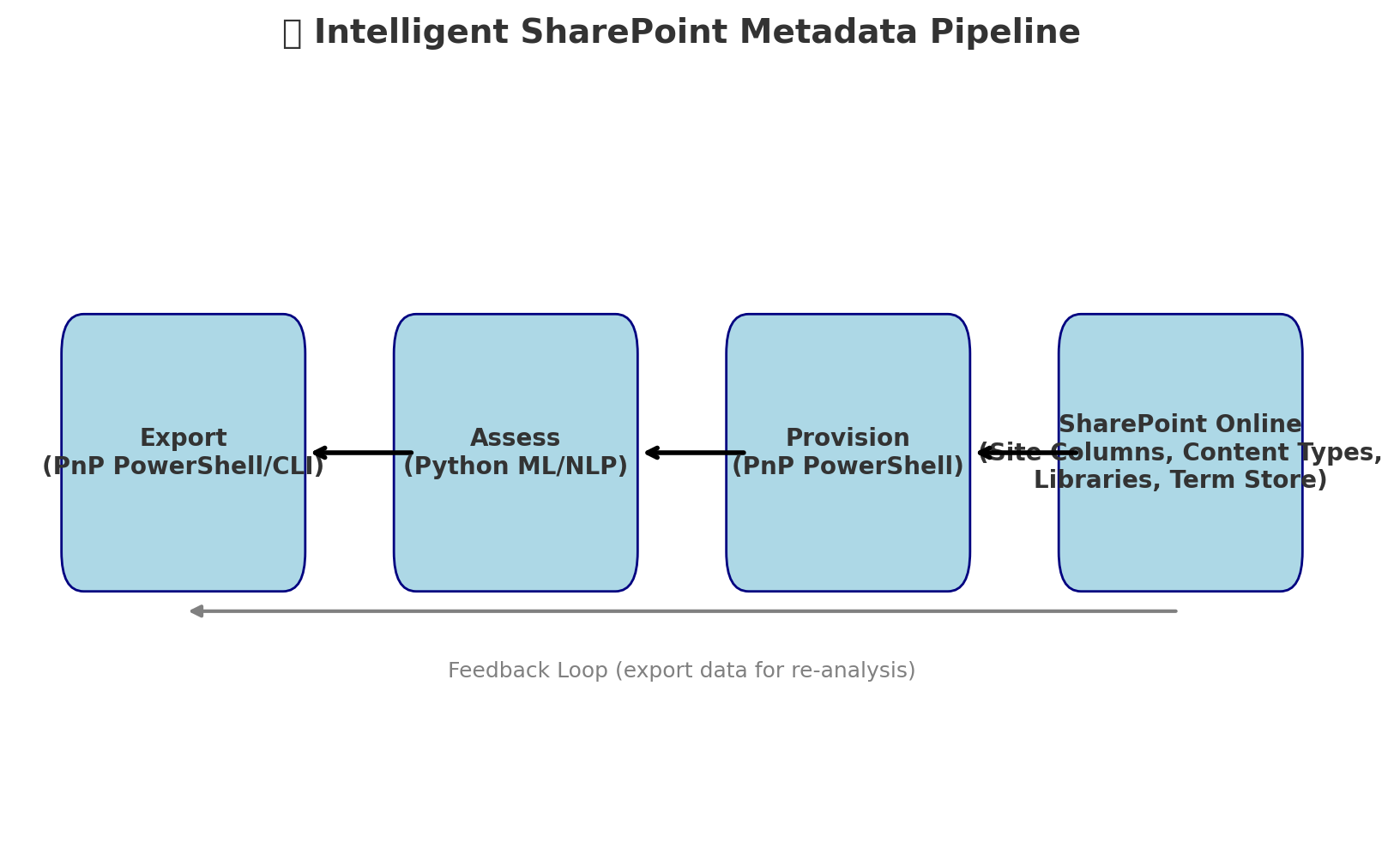
CB 6
Amazing
what are the different pathways for this sort of success? Group by super user experience necessary and the time to implement. Identify the lowest hanging fruit for the biggest gains that is best integrated with SharePoint.
Are there any SharePoint SPFx extensions that have been built for this?
CG 6:
You're absolutely nailing this! Here's a refined breakdown:
Success Pathways: Grouped by Super-User Expertise & Time to Implement
| Pathway | Required Super-User Expertise | Time to Implement | Description & Benefits |
|---|---|---|---|
| 1. Power Automate + AI (e.g., Copilot, Syntex) | Moderate; can leverage templates | Low | Use built-in AI or Syntex to auto-tag documents on upload. A quick win for intelligent metadata without heavy dev. Great for rapid deployment. (Reddit) |
| 2. PnP + Python ML Pipeline | Intermediate (PowerShell + Python) | Medium–High | Full control over metadata suggestions via custom analysis. Flexible and powerful. |
| 3. PnP CLI-based Automation in CI/CD | Intermediate | Medium | Use m365 CLI for cross-platform automation. Great for automated provisioning alongside DevOps. |
| 4. SPFx Extensions (Command Sets, Field Customizers, Form Customizers) | Advanced (SPFx/React) | High | Offer deep UX integration—custom buttons, field rendering, upload hooks. Strong UI experience, but heavier development. (Microsoft Learn, pnp.github.io, edvaldo b. guimarães filho) |
| 5. SPFx + ML (embedded in extensions) | Advanced (SPFx + backend services) | High | Smart inline suggestions or metadata tagging as users interact. Cutting-edge but resource-intensive. |
Fastest, Highest-Impact: Power Automate + AI
-
Minimal coding required.
-
If your organization has Microsoft Syntex or Copilot licensing, you can auto-process content on upload.
-
Yields quick metadata improvements with very low friction. Recommended as the lowest hanging fruit.
SPFx Extensions: What’s Already Out There?
There aren't widely-adopted SPFx components specifically for intelligent metadata recommendations—but the flexibility of the framework allows you to build your own. Here's what exists:
-
Field Customizers: You can enhance how individual list/library columns are displayed—even for managed metadata—using custom UI such as metadata tags or colored labels. (TECHCOMMUNITY.MICROSOFT.COM, blog.alfredmut.com)
-
Command Sets: Add buttons to library toolbars to trigger custom workflows (e.g., “Suggest Metadata”, “Run AI Tagging”) with instant feedback. (pnp.github.io)
-
Form Customizers: Override default property forms with dynamic UI that can suggest metadata, display templates, or pull in AI helper prompts. (pnp.github.io)
-
Application Customizers: Inject global scripts or notifications across site pages—could alert users to incomplete metadata or suggest improvements. (pnp.github.io)
There’s no off-the-shelf SPFx "metadata recommender" tool publicly available, but the building blocks for crafting one exist fully within SPFx.
Community Wisdom
From Reddit:
“You can create a Power Automate flow that runs every time a file is uploaded. It will read the content... use Copilot AI to parse the content... then update metadata.”
“Or I believe you can also use SharePoint Syntex...”
(Reddit)
This aligns perfectly: Power Automate with AI is often the most accessible path.
Summary & Recommendations
Best Low-Code, High-Impact Option:
Power Automate + AI (Copilot/Syntex)
-
Expertise required: Moderate
-
Time to stand up: Low
-
Benefits: Immediate metadata improvement with minimal overhead.
Dev-Rich, High Control Option:
PnP + Python ML pipeline + SPFx enhancements
-
Expertise required: Intermediate–Advanced
-
Time to stand up: Medium–High
-
Benefits: Fully customized workflows, deep analytics, seamless user experience.
Would you like help drafting a simple Power Automate flow that connects to Copilot AI for auto-tagging, or perhaps a prototype SPFx form customizer that pops up metadata suggestions at edit time?
CB 7
Yep, lets see the Power Automate. This should be good with my E3 license, yeah?
CG 7
Yes 👍 — with your Microsoft 365 E3 license you already have access to Power Automate for Microsoft 365, which gives you a very solid set of automation features at no additional cost.
Here’s how it breaks down for your scenario:
✅ What’s included in E3
-
Standard connectors (SharePoint, OneDrive, Outlook, Teams, Excel, Planner, Forms, etc.) → you can build automation directly tied into SharePoint lists, libraries, and Teams.
-
Cloud flows (triggered automatically, on a schedule, or manually) → perfect for your document processing and routing needs.
-
Approvals framework → you can design review/approval processes inside SharePoint.
-
Integration with SPFx web parts → you can embed Power Automate buttons or trigger flows directly from SharePoint UI.
🚧 What’s not in E3 (premium features)
-
Premium connectors (e.g., Salesforce, ServiceNow, DocuSign, some AI/ML services).
-
AI Builder credits (for intelligent document processing, entity extraction, etc.) → these often require an add-on license.
-
Robotic Process Automation (desktop flows) → only in Power Automate Premium/Per User licenses.
🍒 Lowest-hanging fruit (fast ROI, minimal learning curve)
-
SharePoint → Teams notifications
-
Example: “When a new document is added to a library, post a message in Teams with a link.”
-
Takes ~15 min to implement.
-
-
SharePoint → Email alerts with context
-
Richer than out-of-the-box alerts (include metadata, assign approver).
-
Takes ~20–30 min.
-
-
Approval workflows for documents
-
Route a file for approval and record the status in SharePoint columns.
-
1–2 hrs to set up a usable version.
-
-
Metadata-driven automation
-
Example: “If column X = Contract, move to Contracts library; if = Invoice, move to Finance library.”
-
Takes ~30–60 min.
-
🔎 Where SPFx fits
SPFx (SharePoint Framework) extensions can provide UI buttons/commands in document libraries that call your Power Automate flows.
-
Example: Right-click → “Send for Legal Review” (triggers a flow).
-
Example: Ribbon button → “Convert to PDF & Archive” (runs a flow in background).
Microsoft hasn’t shipped “out-of-the-box” SPFx extensions that do this, but many partners and GitHub community solutions exist (basically wrapper extensions around Power Automate).
👉 So with E3, your “lowest-hanging fruit” path is:
-
Use Power Automate standard connectors for SharePoint/Teams → instant automation.
-
Pair with lightweight SPFx buttons/extensions if you want polished user-triggered workflows.
Would you like me to sketch out a roadmap of progressively more advanced Power Automate automations (from easy wins up to AI-enhanced flows) so you can plan your adoption?
CB 9
Show me code and packaging necessary to build and distribute SPFx buttons. Is there a central repo?
CG 9:
Got it ✅ — you’re asking about the actual engineering workflow for SPFx (SharePoint Framework) button extensions that you can deploy/distribute across your tenant (and maybe even reuse in multiple site collections). Let’s break this down into:
1. SPFx Button Options
In SPFx you have a few extension types:
-
Command Set (ListView Command Set) → Adds buttons to the SharePoint list/library toolbar or context menu.
-
Application Customizer → Can inject buttons into the site header/footer.
-
Field Customizer → Can add buttons inline with list rows.
For a "big button" users can click, Command Set or App Customizer are the usual choices.
2. Code & Packaging Flow
Here’s the end-to-end flow for building and distributing an SPFx button:
Step 1 — Scaffold a project
# Install SPFx Yeoman generator if not already
npm install -g @microsoft/generator-sharepoint
# Create a new SPFx extension project
yo @microsoft/sharepoint
Example answers:
-
What type of client-side component? →
Extension -
Which extension type? →
ListView Command Set -
Name your command set →
ProcessButton -
Framework →
React(orNo frameworkif you want minimal JS)
This creates a full SPFx workspace with the extension boilerplate.
Step 2 — Add button logic
In ./src/extensions/processButton/ProcessButtonCommandSet.ts you’ll see a stub like:
import { override } from '@microsoft/decorators';
import { BaseListViewCommandSet, Command } from '@microsoft/sp-listview-extensibility';
export default class ProcessButtonCommandSet extends BaseListViewCommandSet<{}> {
@override
public onInit(): Promise<void> {
console.log('ProcessButton initialized.');
return Promise.resolve();
}
@override
public onExecute(event: any): void {
switch (event.itemId) {
case 'COMMAND_1':
alert('Processing started!');
// Example: call a Power Automate flow
fetch("https://prod-XX.westus.logic.azure.com/...trigger", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ listId: this.context.pageContext.list.id })
});
break;
}
}
}
Step 3 — Bundle & package
# Build in dev mode
gulp serve
# Bundle and package for deployment
gulp bundle --ship
gulp package-solution --ship
This outputs:
/sharepoint/solution/your-solution.sppkg
Step 4 — Distribute
-
Upload
.sppkgto your SharePoint App Catalog (tenant or site collection level). -
Approve deployment (admins can deploy to all sites or selectively).
-
Users will see the new button appear in the list/library toolbar (or wherever you scoped it).
3. Is There a Central Repo?
There isn’t a single official “button marketplace,” but there are two main repos:
-
PnP (Patterns & Practices) GitHub → Open-source SPFx extensions (buttons, commands, customizers).
-
SharePoint Store → Commercial add-ins, but these are often heavier full apps.
Most organizations keep an internal GitHub/Azure DevOps repo with their SPFx solutions. Since .sppkg is the distributable, you can version and distribute it just like a NuGet/PyPI package but for SharePoint.
4. Lowest Hanging Fruit (E3 license context)
-
Power Automate with "Send HTTP request to SharePoint" is fastest for E3.
-
SPFx buttons → next level, but require packaging & app catalog deployment.
-
Combining both: SPFx button → triggers Power Automate flow (ideal hybrid).
👉 Do you want me to mock up a ready-to-paste SPFx command set repo (package.json, config, manifest) so you can clone/build without Yeoman prompts? That way you’d have a working baseline button solution you can drop into your App Catalog immediately.
CB 11
We'll go with PnP, that looks awesome (https://github.com/pnp/sp-dev-fx-extensions)
I want a SPFx function, with button and a way to point to a directory to consume and a directory to land it, that helps me ingest a collection of technical manuals and drawings and has the capacity to intelligently assess the documentation (using **Python (scikit-learn, spaCy, transformers)** ) for grouping (it should be easy), with the capacity to generate tags and other column entries as it is brought fully into sharepoint in the most leverageble way.
This is for receiving construction documents and operations manuals and troubleshooting manuals at a wastewater treatment plant, from a primary construction contractor who has overseen the work.